Project 5 - Part 2
1. Data Set Up
In order to work with the data there were a few steps I had to do first. After bringing the dataset into my workspace, I removed all the NaNs and changed all the values to integers. These steps proved to be very helpful in order to get started on the stuff I needed to do. I was also able to see the types of each of the columns.
pns = pd.read_csv('city_persons.csv')
check_nan = pns['age'].isnull().values.any()
pns.dropna(inplace=True)
pns.reset_index(drop=True, inplace=True)
pns['age'] = pns['age'].astype(int)
pns['edu'] = pns['edu'].astype(int)
display(pns.dtypes)
X = pns.drop(["wealthC"],axis = 1)
y = pns.wealthC
2. K-Nearest Neighbors
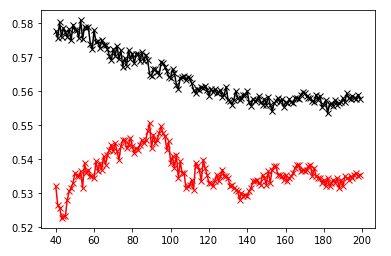
When executing a KNN classification method, the best results produced from a range of 40 to 200 resulted in a testing score of 0.55051. When performing a KNN and adding a distance weight, the classification method produced a smalled testing score. It produced a score of 0.50024.
3. Logistic Regression
Next, a logistic regression was executed. It resulted in a testing score of 0.55949. This higher testing score shows the logistic regressioned was better in comparison to the KNN that was previously produced. But it is only slightly better, not by a large number.
4. Random Forest
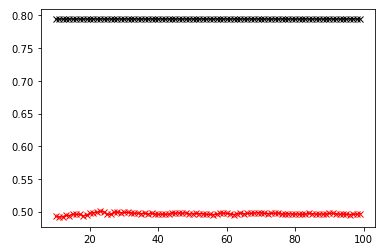
Next, a random forest was performed to produce the results. The number of estimators (or trees) to 100, 500, 1000, and 5000 with specifications is most likely to return the best model. The training and testing score for 100 trees was 0.7972005 and 0.4997559, respectively. The training and testing score for 500 trees was 0.7972005 and 0.4904831, respectively. The training and testing score for 1000 trees was 0.7972005 and 0.4982918, respectively. The training and testing score for 5000 trees was 0.7972005 and 0.4953636, respectively. These have decently high score of accuracy. The 100 trees produced the best results.
After that, I tested the minimum number of samples that was required to split an internal from my range of 20 to 30 and found it to be 27 with a testing score of 0.56785. Which is not that much higher than the previous models as it is a very close number to them.
Next I ran models of standardized data and unstandardized data and compared the results. The standardized and unstandardized score for 100 trees was 0.4988038 and 0.4977799, respectively. The standardized and unstandardized score for 500 trees was 0.5146364 and 0.5043972, respectively. The standardized and unstandardized score for 1000 trees was 0.5280527 and 0.5056125, respectively. The standardized and unstandardized score for 5000 trees was 0.5114690 and 0.5046364, respectively. 1000 trees produced the best results compared to the rest. The standardized data had better and higher scores of accuracy than the unstandardized scores.
5. Recoding Wealth Class 2 & 3
With the previous steps done again, there was a difference from before with recoding the wealth classes 2 and 3 into a single outcome. I redid all of the previous models to see the results with the recoding.
The KNN testing score for the recoding was 0.60093 . And when adding the distance weight, the testing score was 0.59015. The testing score for the recoding was overall was higher than before with wealth class 2 and 3 split now. Also when adding the distance weight, the testing score was lower than without the distance weight.
For the logistic regression, the testing score when executed was 0.61274. The logistic regression score increased compared to the logistic regression from before. Compared to the KNN and KNN with distance for the recoded wealth 2 & 3 data, the logistic regression is higher than both of those.
With the random forest, results were produced with the recoded wealth class 2 & 3. The standardized data and unstandardized data was executed and results were compared. The standardized and unstandardized score for 100 trees was 0.5946065 and 0.5865315, respectively. The standardized and unstandardized score for 500 trees was 0.5986135 and 0.5916847, respectively. The standardized and unstandardized score for 1000 trees was 0.5763152 and 0.5881637, respectively. The standardized and unstandardized score for 5000 trees was 0.5986349 and 0.5831532, respectively. There may be a possible reason for this change in results and that being with the recoding of wealth class 2 and 3, there was less variance among the data, thus changing how accurate and well predicted it was making it have a greater accuracy. These numbers are consistantly higher than the previous standardized and unstandardized data without the recoding of wealth class 2 and 3.
6. Result Analysis
Overall, the recoded dataset where the recoding of wealth class 2 and 3 into a single outocme came out with better results over all of the models when compared to the split wealth class 2 & 3 for the wealth of all persons throughout the large West African capital city that was described. The scores are visibily higher. But between the models of the original data, the model that produced the best results was the logistic regression. And between the models of the recoded wealth 2 & 3 data, the model that produced the best results was the logistic regression, again. This data was quite easier to work with than compared to the previous data set of another West African city with wealthC and wealthI.