Project 2
1.
Continuous data is data that keeps changing or keeps updating. An example of continuous data would be a person’s age or a person’s height. Ordinal data is data where the order of values but not the difference. An example of ordinal data would be 1st, 2nd, and 3rd place in a race. Nominal data is data that is categorical. Examples of nominal data are countries, occupations, or genders.
A model of my own construction is a randomly selected group of people which I would ask to run in a 5k race. Before the race, I would ask for people’s ages and their genders. Their ages and times would be the continuous data. Their genders would be the nominal data. Their placement at the end of completing the 5K would be the ordinal data. The features would be the gender and age while the targets would be the placements and times. We would then be able to see the relationship between the runner’s placements and timings.
2.
Normal Distribution
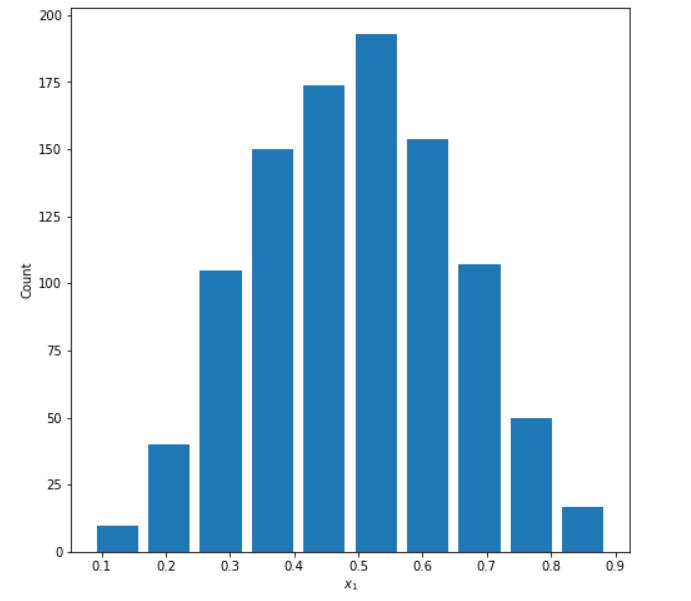
Mean: 0.496
Median: 0.499
This distribution follows the bell curve
Left Skewed Distribution
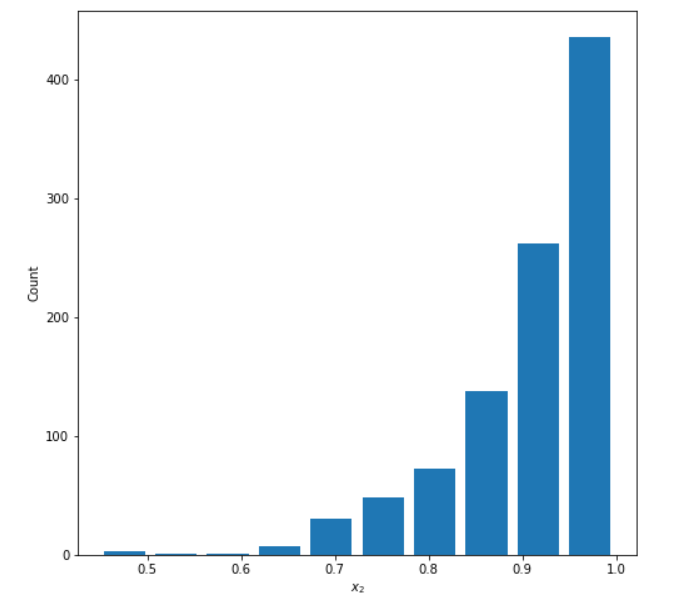
Mean: 0.909
Median: 0.933
Right Skewed Distribution
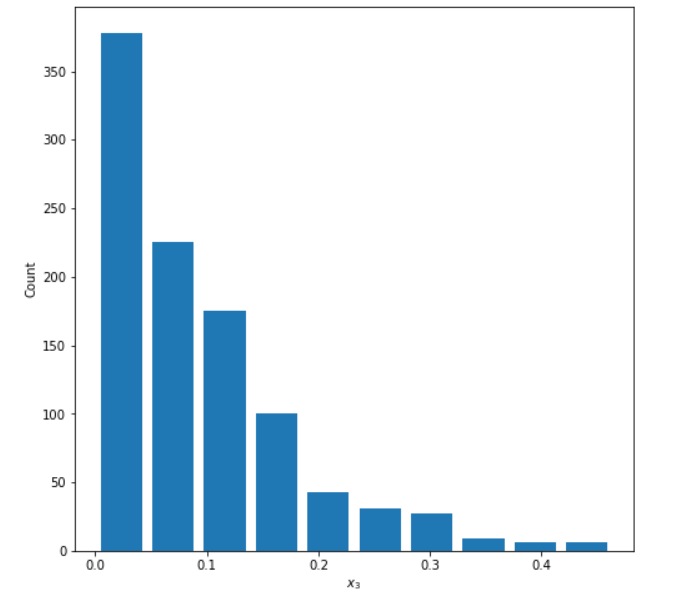
Mean: 0.093
Median: 0.070
Looking at all the distributions, as the alpha value becomes larger, we can see that the bulk of the distribution shift more toward the right and as the beta becomes smaller, we can see that the distribution moves more toward the left.
3.
Raw Data
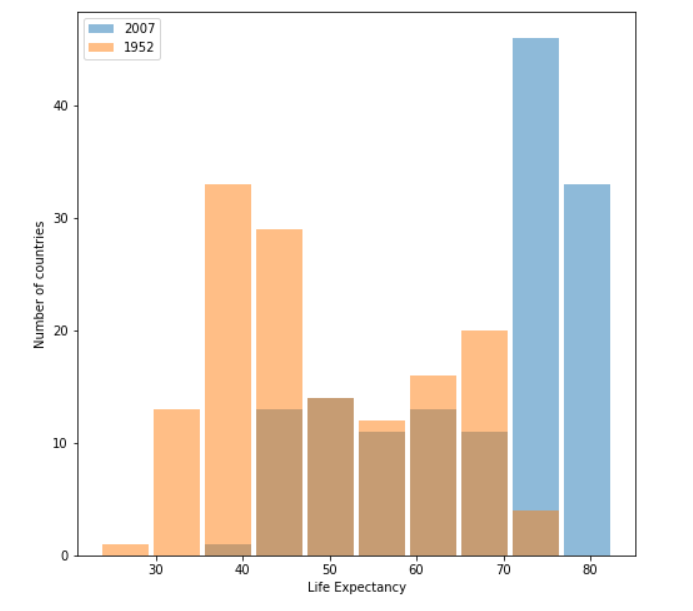
Log Transformation Data
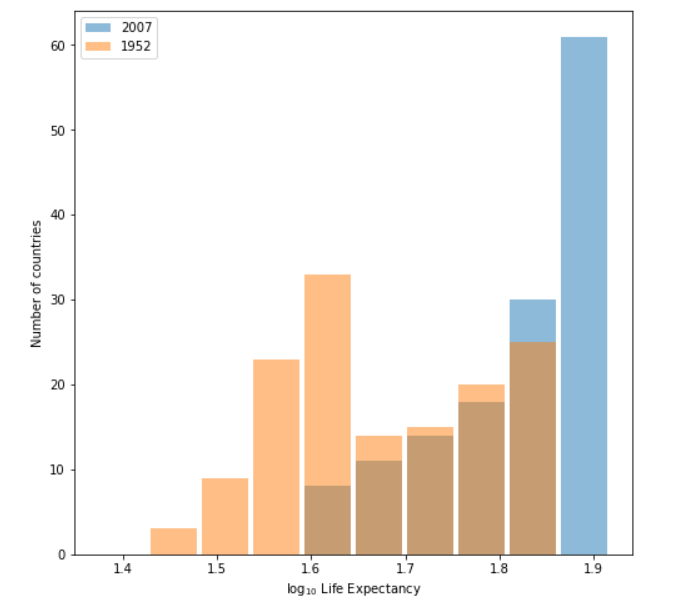
Of the two resulting plots, the log transformation data plot best communicates the change in life expectancy amongst all of the countries from 1952 to 2007. We are able to clearly see the differences between the two years with the overlapping histogram produced with the log transformation. There is an upward trend that is detectable for life expectancy. The first data makes it hard to see the trend as opposed to the log transformation data because we can see it on a better scale. The raw data is more spread out, having variance, so the log transformation gives a better measure of it all.
4.
Raw Box & Whisker
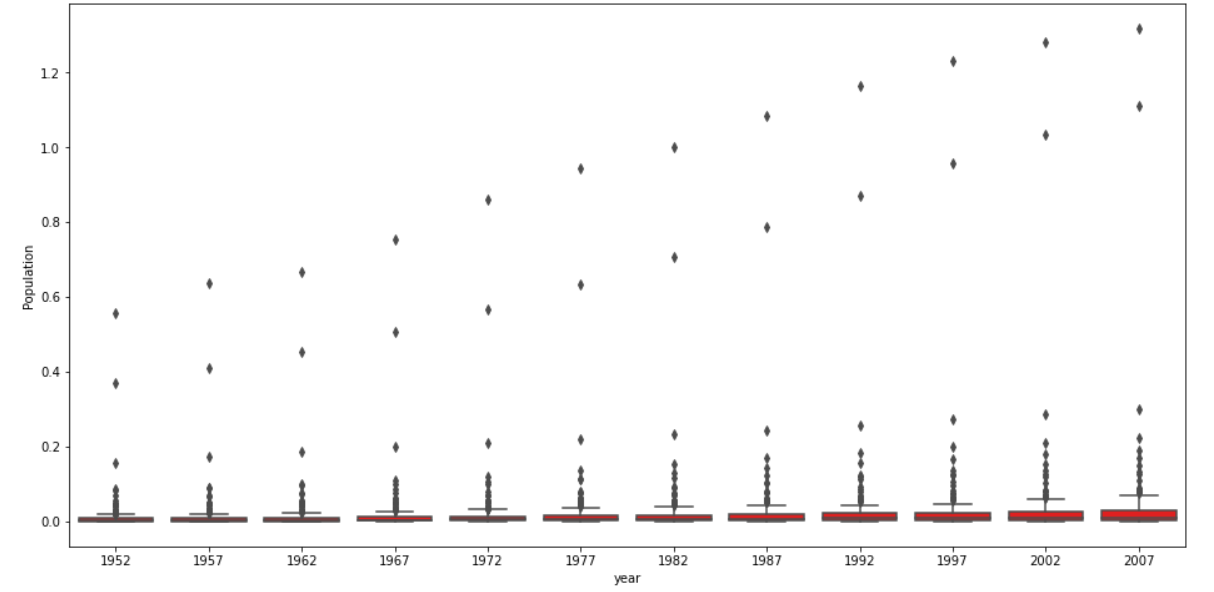
Log Transformation Box & Whisker
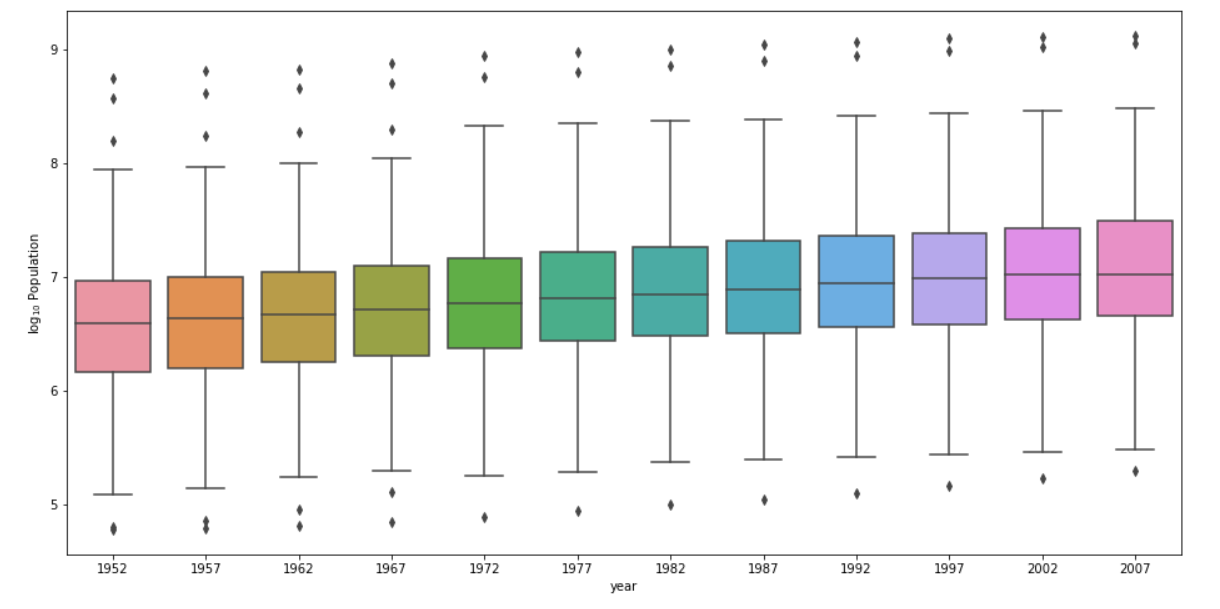
Of the two resulting plots, the log transformation box and whisker plot clearly best communicates the change in population amongst all of these countries from 1952 to 2007. We are able to clearly see the boxplots and their values on the log transformation plot which we are unable to see on the raw data plot. It is way more spread out and readable for us to clearly analyze the data. The first plot is way too squished together and tiny with large outliers to see anything; the large outliers deviate remarkably from the mean and median. The log transformation reduced the difference between the outliers, mean, and median.