Project 1
1.
A package is collection which contains a ton of modules which have certain capabilities. A library is essentially a bunch of useful functions that can be used whenever and perform common tasks. In order to use a package you have to first install the package from the interpreter (in Pycharm, click on Python Interpreter and then the + sign and install the package wanted) and then import it into your workspace. import numpy as np or import pandas as pd or from datetime import datetimeare examples we have used in class. By importing pandas as ‘pd’ (‘pd’ is the alias), the alias allows for cleaner, simpler, and shorter code.
2.
A data frame is like a chart with multiple rows and columns of information that can be sifted through. The Pandas library is useful for working with data frames. To read a file from its remote location you can use the .read_csv() command. Example:
path_to_data = 'gapminder.tsv'
data = pd.read_csv(path_to_data, sep='\t')
This shows how to read a file and import it into the work session. Specificying an arguement within the read() function is significant because in the example about the data is a .tsv, so it is tab separated, thus needing to add the sep='\t' argument into the read_csv() part.
Example of data frame I created from the code snippet above:
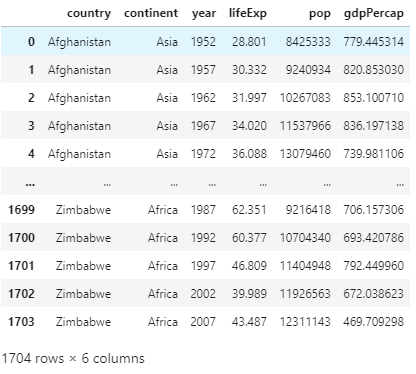
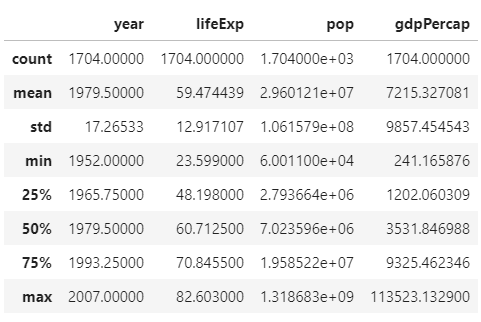
The description of data can be seen by data.describe() or data.info(). The number of rows and columns can be determined by data.shape. Columns can also be seen by data.columns. Alternate terminology for decribing rows and columns is index and series or values and outcomes.
3.
The year variable exhibits regular intervals of 5 years starting with 1952. Adding data from 2012 and 2017 would make it more current. 284 new outcomes would be added to the data frame; 142 for each year added.
4.
The country Rwanda in Africa had the lowest life expectancy of 23.599 in the year of 1992. The reason for this is the Rwandan Genocide at the time where lots of people died as well as the poor living and health conditions overall.
5.
The last column shows the Total GDP for the countries in 2002:
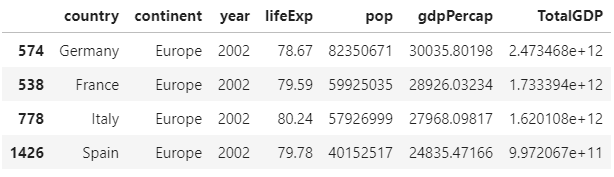
The last column shows the Total GDP for the countries in 2007:
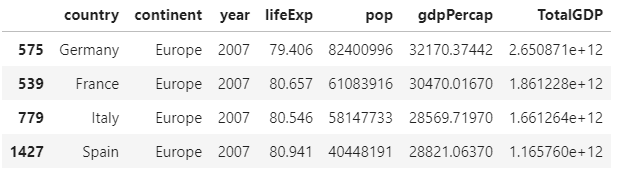
Spain exhibited the most significant increase in Total GDP during the previous 5-year period.
6.
The & is the AND operator. It compares two operands and returns TRUE if both operands are true. It is useful in finding data that has multiple criteria for example data_asia = data[(data['continent']=='Asia') & (data['year'] == data['year'].max())]. This only adds to the index if both conditions are true.
The == is the EQUAL TO operator. It compares two operands and returns TRUE if both operands are equal. Example in programming: data_asia = data[(data['continent']=='Asia')]. This adds to the index wherever the continent is Asia is true. This is useful for finding specific data.
The | is the OR operator. It compares two operands and returns TRUE if either operand, or both, is true. Example in programming: ex_country = data[(data['country']=='Germany') | (data['country']=='France')]. This adds to the index wherever the country is Germany or the country is France is true. This is useful for finding data that doesn’t need to fit all of the criteria.
The ^ is the XOR operator and compares operands and returns TRUE if only one operand is true but returns FALSE if both are true or both are false. Example: ('bob' == 'joe') ^ (21>20) will return TRUE. This is useful for finding data where only one condition must be met.
7.
The .loc gets information by using its label, while .iloc gets information from its integer position. Examples and how to extract a series of consecutive observations from a data frame: data_asia.loc[11] and data_asia.iloc[[1,2,3,4,5,6,7],[1,2,3]]. This gives all observations from a series of consecutive columns data_asia.iloc[:, 0:5]
8.
An API stands for Application Programming Interface. It is used to access data by send and get requests for data. Here is an example of how to construct a request to a remote server, write a local file, and then import it into the work session:
import requests
import os
data_folder = 'data'
if not os.path.exists(data_folder):
os.makedirs(data_folder)
url = 'https://api.covidtracking.com/v1/states/daily.csv'
file_name_short = 'ctp_' + str(dt.now(tz = pytz.utc)).replace(' ', '_') + '.csv'
file_name = os.path.join(data_folder, file_name_short)
r = requests.get(url)
with open(file_name, 'wb') as f:
f.write(r.content)
import pandas as pd
df = pd.read_csv(file_name)
9.
The .apply() is a method where a function gets inputted and applied to all values in the data frame. Using .apply() is an alternative to .iterrows() to write a loop. The .apply() is the preferred approach because cleaner, simpler, and more efficient as we don’t have to write a loop.
10.
An alterative approach to .iloc is to simply print the columns that are wanted like so: print(gapmind_data[['country', 'year', 'pop']]). A way to select, filter and assign a subset number of variables to a new data frame is to do something like this (example is very low tech): newframe = data[data['continent']=='Asia']. We can also index and slice like this: data_asia[data_asia.columns[1:5]]